بهبود بازده در محرکه های القایی با الگوریتم Q-Learning
دانلود رایگان مقاله : روش هوشمند جدید یادگیری تقویتی برای کاهش تلفات در موتورهای القایی
چکیده
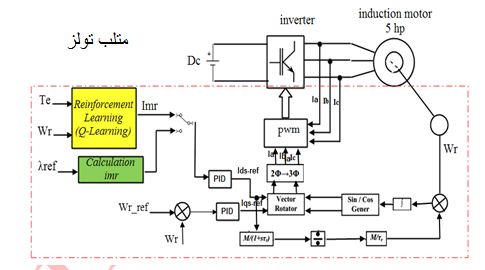
یادگیری تقویتی روشی است که در آن عامل با در نظر گرفتن حالت محیط، از بین همه اعمال ممکن ،یکی را انتخاب می کند و محیط در ازای انجام آن عمل، یک سیگنال عددی به نام پاداش به عامل باز می گرداند. هدف عامل این است که از طریق سعی و خطا سیاستی را بیابد که با دنبال کردن آن به بیشترین پاداش ممکن برسد. در این مقاله ، سعی داریم به عامل یاد بدهیم چگونه تلفات موتور القایی را کاهش بدهد. ایده اصلی ،استفاده از الگوریتم Q-Learning برای یافتن بهترین و بهینه ترین عمل در هر حالت از محیط می باشد. حالت های الگوریتم شامل گشتاور الکترومغناطیسی (Te) و سرعت موتور (wr) بوده و عمل ، جریان مغناطیسی imr می باشد.
کلمات کلیدی: یادگیری تقویتی ،الگوریتم Q-Learning ، موتور القایی ، کاهش تلفات.
مقدمه
یادگیری تقویتی یعنی مسیر یابی از موقعیت به عمل به گونه ای که پاداش عددی آن عمل حداکثر باشد. در این روش به یادگیرنده گفته نمی شود که چه اقدامی بایستی انتخاب شود، بلکه او خود باید با امتحان کردن اقدام های ممکن, عمل با بالا ترین پاداش را کشف کند. یکی از روش های یادگیری تقویتی که پیاده سازی راحتی دارد ، روش Q-Learning است که در سال ۱۹۸۹ توسط واتکینز ارائه گردید[۱] . این الگوریتم توسط عامل برای یادگیری از طریق تجربیات یا آموزش استفاده می شود،هر تکرار معادل با یک دوره آموزش است. هدف از آموزش ساخت مغز عامل است ، که توسط ماتریس Q نمایش داده می شود. آموزش بیشتر منجرو به ماتریس Q بهتری خواهد شد ، که می تواند توسط عامل برای حرکت در مسیر بهینه استفاده شود. بدین ترتیب با داشتن ماتریس Q ، عامل می تواند در عوض کاوش و جستجوی متعدد ، با رجوع به ماتریس حالات و انتخاب گزینه ماکزیمم ، بهترین حالت را انتخاب نماید[۲-۳]. علاقه به استفاده از روش های یادگیری تقویتی برای کاربرد های کنترلی روزمره به سرعت در حال رشد است به عنوان مثال در مراجع [۴-۱۲] دیده می شود. در این مقاله ما روی سیستم کنترل درایو موتور القایی متمرکز شده ایم. برای طراحی این سیستم ، این طور فرض شده که عامل از سیستم درایو هیچ اطلاعی ندارد. در مقابل آن ، اینجا ، فرض شده که عامل ، قادر به جمع آوری حالت ها و عمل های سیستم طی رفتار واقعی موتور می باشد. یادگیری از طریق تعامل با سیستم واقعی دارای مزیت هایی همچون :
- احتیاجی به دانش اولیه درباره سیاست یادگیرنده ندارد. این مزیت سبب شده تا ما مقید به انجام یکسری از قانون کنترلی اولیه در مسائل کنترل کننده نباشیم.
- رویکرد یادگیری تقویتی در شرایطی که هیچ ایده ای در مورد قانون کنترل کاری نیست ، نیز قابل اجراست [۱۳] .
- قابلیت دیگر یادگیری تقویتی ، عدم نیاز به داده های آموزشی بوده که نسبت به مراجع [۳,۷,۱۰,۱۴] از برتری چشم گیری برخوردار است. در واقع به عامل گفته نمی شود که عمل صحیح در هر وضعیت چیست ، و فقط با استفاده از یک معیار اسکالر که سیگنال تقویتی نامیده می شود ، خوب یا بد بودن عمل به عامل نشان داده می شود. عامل موظف است با در دسترس داشتن این اطلاعات ، یاد بگیرد که بهترین عمل کدام است. این ویژگی یکی از نقطه قوتهای خاص الگوریتم یادگیری تقویتی است.
سایر بخش های این مقاله به صورت زیر می باشند. در بخش ۲ ، اساس یادگیری تقویتی و الگوریتم های q-learning و e-greedy به صورت اجمالی توضیح داده خواهد شد. در بخش ۳، مدل موتور القایی همراه با تلفات و براساس مدار معادل جریان مغناطیسی روتور بیان می شود. در بخش ۴ ، براساس مطالب بخش ۲و۳ ، به ارائه دیدگاه پیشنهادی ، استفاده از یادگیری تقویتی در کاهش تلفات موتور القایی خواهیم پرداخت. در بخش ۵ ، نتایج شبیه سازی که با نرم افزار matlab انجام شده ، مورد بررسی قرار گرفته است. بخش ۶ نیز ، حاوی بیان نتایج کلی مقاله است.
نوع مقاله: کنفرانسی و isc
اولین مسابقه کنفرانس بین المللی جامع علوم مهندسی ، پایگاه استنادی علوم جهان اسلام (ISC)
نویسندگان: صادق حصاری ، ساجده اربابی
———————————————————————————————-
دانلود: دانلود رایگان اصل مقاله
برای عضویت روی عکس زیر کلیک کنید : (آخرین اخبار مرتبط با مهندسی و سایر تکنولوژی ها)

یا آدرس لینک زیر را در تلگرام خود جستجو نمایید:
m_b_coll@
مجموعه: ماشین های الکتریکی, یادگیری تقویتی