یادگیری تقویتی : یک مرور ویژه و کارهای پیشرو + همراه با شبیه سازی مقاله
پروژه ۱۲۰۸: شبیه سازی مقاله در متلب
خلاصه:
در سال های اخیر یادگیری تقویتی بنام برنامه ریزی دینامیکی تطبیقی نام ذاری شده است. و به عنوان یک ابزار مفید برای حل مسائل پی در پی در تئوری کنترل به کار می رود. اگر چه چندین تحقیق در این حوزه در هوش مصنوعی ، چندین موفقیت قابل توجه به چشم می خورد. در مسائل پیچیده و ابعاد بزرگ در بهینه سازی دینامیک، بویژه در مسائل تصمیم گیری مارکوف ، قدرت یادگیری تقویتی بیشتر به چشم می خورد. همانطور که می دانیم در سال های اخیر در مسائل دارای ابعاد بالا از جمله مسائلی که دارای نفرین ابعاد در برنامه ریزی پویا دارند، بیشتر به چشم می خورد. وجود یادگیری تقویتی به صورت مستقیم در این مسائل اجازه می دهد تا اینگونه مسائل به سادگی حل شوند. موفقیت یادگیری تقویتی بستگی به ریشه های ریاضیاتی قوی در اصل برنامه ریزی پویا، شبیه سازی مونت کارلو، تقریب توابع و هوش مصنوعی دارد. موضوعات در این مقاله مروری شامل : Temporal di®erences, Q-Learning, semi-MDPs and stochastic games.
چندین کار اخیر در یادگیری تقویتی شامل گرادیان سیاست و یادگیری تقویتی سلسله مراتبی پیشنهاد شده است. چند مثال کاربردی مورد بررسی قرار گرفته است. این مقاله هدفش آشکار کردن ریشه های ریاضی که خواننده قادر است آنها را در تحقیقاتشان بهره ببرند. این مقاله بیش از ۱۰۰ رفرنس را مورد بررسی قرار داده است.
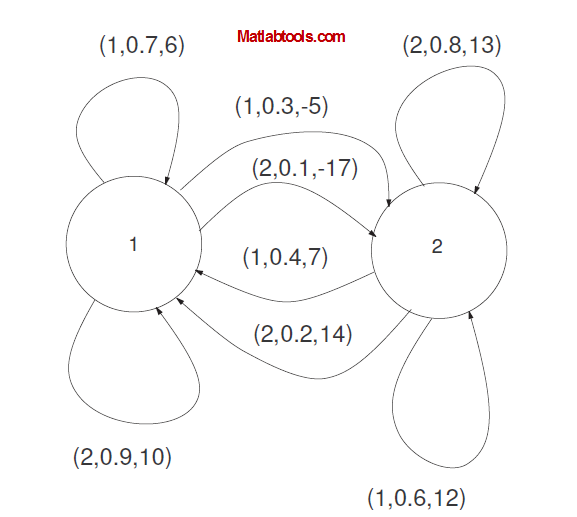
در این پروژه بررسی چند شبیه سازی که در متن به آن اشاره شده در نرم افزار متلب صورت رفته است.
دانلود: دانلود اصل مقاله لاتین
در صورت سوال در مورد محصول می توانید از بخش تماس با ما (منوی بالا)، با شماره تلفن مورد نظر مکاتبه نمایید.
برخی نتایج:


rho =
۱۱٫۰۴۰۰
semivar_risk =
۱۸٫۷۲۰۰
rho =
۱۱٫۰۴۰۰
semivar_risk =
۱۸٫۷۲۰۰
rho =
۱۱٫۰۴۰۰
semivar_risk =
۱۸٫۷۲۰۰
score =
۸٫۲۳۲۰
مجموعه: یادگیری تقویتی